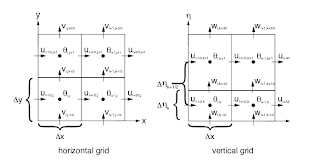
My goal here is to give a simple overview of the WRF for computer science students. The Weather Resarch and Forecasting (WRF, pronounced "worf") model is an open-source numerical weather prediction (NWP) and atmospheric simulation system designed for both research and operational applications [1]. This system was developed as joint effort between National Center of Atmospheric Research, National Oceanic and Atmospheric Administration (NOAA), Air Force Weather Agency and others. In this post ,and the posts to follow, I'll try to explain the WRF from two different perspectives, the first being Meteorology and the second being Computer Science. I am here concerned with the Advanced Research WRF (ARW) subset of WRF. Weather Prediction Basics: Weather Prediction means to predict the state of the atmosphere in terms of (pressure, temperature, speed of wind, etc). Our atmosphere is controlled by flow and the conditions of the air across the planet and by predicting that fl...